一、操作系统
1、操作系统四大特性
(1)并发
a、并发与并行的区别
b、单核与多核的并发与并行
c、引入进程实现并发
(2)共享
共享是指系统中的资源可以被多个并发进程共同使用,互斥共享的资源称为临界资源
- 互斥共享
- 同时共享
(3)虚拟
虚拟技术把一个物理实体转换为多个逻辑实体
时分复用技术
多个进程能在同一个处理器上并发
空分复用技术
多个程序同时放入内存中,互不影响
所谓虚拟是指通过某项技术把一个物理实体变为若干个逻辑上的对应
(4)异步
描述的是进程这种以不可预知的速度走走停停、何时开始何时暂停何时结束不可预知的性质
二、计算机网络
1、HTTP发展
(1)HTTP 0.9
只支持 GET 请求
(2)HTTP 1.0
优化点:
请求方式的多样化
增加了 POST 命令和 HEAD 命令
支持发送任何格式的内容
图片、视频、音频等等
请求和回应的格式
头信息、状态码、缓存
缺点:
- 连接无法复用
- Head-Of-Line Blocking(HOLB,队头阻塞)
(3)HTTP 1.1
优化点:
缓存处理
增加了缓存头来控制缓存策略
带宽优化及网络连接的使用
引入了range头域,允许只请求资源的某个部分
错误通知的管理
增加了错误码
长链接
keep-alive 可以复用一部分连接,传送多个 HTTP 请求和响应
缺点:
域名分片等情况下仍然需要建立多个 connection
pipeling 只部分解决了 HOLB
没有解决服务器的队头阻塞,服务器只能按序处理连接请求
协议开销大
header 里携带的内容过大
(4)HTTP 2.0
二进制格式传输数据
解析起来更高效
支持对 Header 压缩
多路复用
多路复用很好地解决了浏览器限制同一个域名下的请求数量的问题
三、数据库
1、如何保证Redis的高可用
(1)哨兵模式
(2)集群分区
(3)节点通信机制
2、索引的分类
按数据结构分类可分为:B+tree索引、Hash索引、Full-text索引
Hash索引适于key-value查询,通过Hash索引比B-tree索引查询更加迅速,但Hash索引不支持范围查找例如<><==,>==等
按物理存储分类可分为:聚簇索引、二级索引(辅助索引)
按字段特性分类可分为:主键索引、普通索引、前缀索引
按字段个数分类可分为:单列索引、联合索引(复合索引、组合索引)
3、你平时是怎么建立索引的
有什么技巧或者需要考虑的
(1)索引的类型
UNIQUE(唯一索引)
不可以出现相同的值,可以有NULL值
INDEX(普通索引)
允许出现相同的索引内容
PRIMARY KEY(主键索引)
不允许出现相同的值,且不能为NULL值,一个表只能有一个primary_key索引
fulltext index(全文索引)
上述三种索引都是针对列的值发挥作用,但全文索引,可以针对值中的某个单词,比如一篇文章中的某个词,然而并没有什么卵用,因为只有myisam以及英文支持,并且效率低
(2)创建索引的技巧
维度高的列创建索引
数据列中不重复值出现的个数,这个数量越高,维度就越高
如数据表中存在8行数据a,b ,c,d,a,b,c,d这个表的维度为4
要为维度高的列创建索引,如性别和年龄,那年龄的维度就高于性别。性别这样的列不适合创建索引,因为维度过低
对 where、on、group by、order by 中出现的列使用索引
对较小的数据列使用索引
这样会使索引文件更小,同时内存中也可以装载更多的索引键
为较长的字符串使用前缀索引
不要过多创建索引,除了增加额外的磁盘空间外,对于DML操作的速度影响很大,因为其每增删改一次就得从新建立索引
使用组合索引,可以减少文件索引大小,在使用时速度要优于多个单列索引
4、联合索引和单独建立索引的区别
5、SQL你平时是怎么优化查询的
(1)MySQL优化的五个原则
减少数据的访问
压缩、索引等手段减少磁盘IO
返回更少的数据
只返回需要的字段和数据分页处理,减少磁盘 IO 及网络 IO
减少交互次数
批量 DML 操作,函数存储等减少数据连接次数
减少服务器 CPU 开销
减少数据库排序操作以及全表查询,减少 CPU 内存占用
利用更多资源
使用表分区,可以增加并行操作,更大限度利用 CPU 资源
总结到SQL:
- 最大化利用索引
- 尽可能避免全表扫描
- 减少无效数据的查询
(2)避免不走索引的场景
避免在字段开头模糊查询,会导致数据库放弃索引全表扫描
如:
SELECT * FROM t WHERE username LIKE '%陈%'改为:
SELECT * FROM t WHERE username LIKE '陈%'尽量避免使用 in 和 not in,会导致引擎走全表扫描
如果是子查询,可以用 exists 代替
如:
select * from A where A.id in (select id from B);改为:
select * from A where exists (select * from B where B.id = A.id);尽量避免使用 or,会导致数据库引擎放弃索引进行全表扫描
可以用 union 代替 or,如下:
SELECT * FROM t WHERE id = 1 OR id = 3改为SELECT * FROM t WHERE id = 1 UNION SELECT * FROM t WHERE id = 3尽量避免进行 null 值的判断,会导致数据库引擎放弃索引进行全表扫描
如:
SELECT * FROM t WHERE score IS NULL改为0值判断:
SELECT * FROM t WHERE score = 0查询条件不能用 <> 或者 !=
使用索引列作为条件进行查询时,需要避免使用<>或者!=等判断条件
order by 条件要与 where 中条件一致,否则 order by 不会利用索引进行排序
如:
SELECT * FROM t order by age;改为:
SELECT * FROM t where age > 0 order by age;
6、一致性Hash
分布式缓存
7、Nginx能做什么
https://juejin.cn/post/6844903670434250759
反向代理
反向代理(Reverse Proxy)方式是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个反向代理服务器
负载均衡
摊到多个操作单元上进行执行
HTTP服务器(包含动静分离)
正向代理
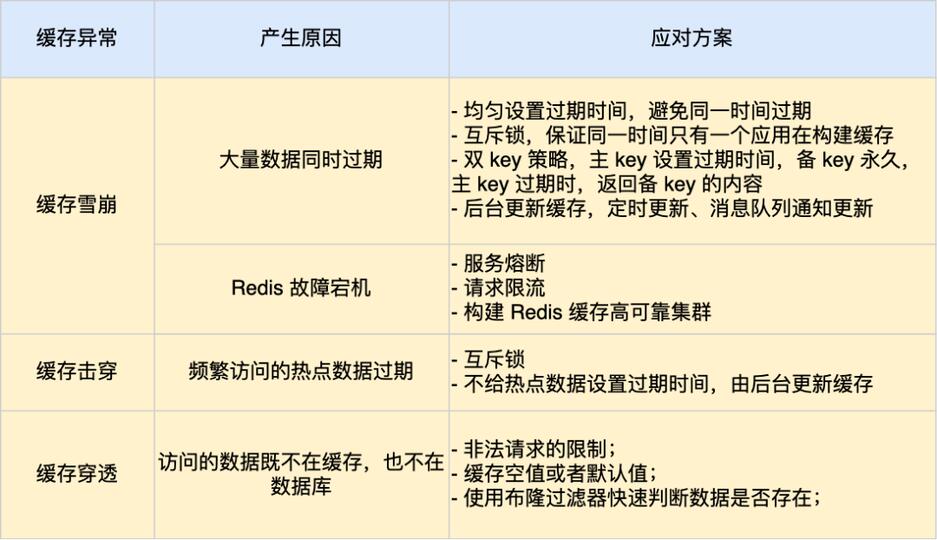
8、Redis缓存异常
- 雪崩
- 击穿
- 穿透
四、数据结构与算法
1、简单讲讲B+Tree
https://zhuanlan.zhihu.com/p/27700617
2、栈溢出Stack Overflow
(1)什么是栈溢出
栈溢出指的是程序向栈中某个变量中写入的字节数超过了这个变量本身所申请的字节数,因而导致栈中与其相邻的变量的值被改变
(2)栈溢出的原因
局部数组过大
局部变量是在栈中分配的
递归调用层次太多
递归函数在执行的时候会进行压栈操作
指针或者数组越界
例如字符串拷贝的时候