一、Vocabulary
1. sedentary
adj.需要久坐的;长期伏案的
2.majority
n.大多数; adj.多数人支持的
NumPy是Python的一个用于科学计算的基础包。它提供了多维数组对象,多种衍生的对象(例如隐藏数组和矩阵)和一个用于数组快速运算的混合的程序,包括数学,逻辑,排序,选择,I/O,离散傅立叶变换,基础线性代数,基础统计操作,随机模拟等等。–摘自知乎
NumPy提供了两种基本的对象: ndarray和 ufunc. ndarray是存储单一数据类型的多维数组, 而ufunc则是对数组处理的函数
NumPy封装了一种新的数据类型: ndarray, 一个多维数组对象, 该对象封装了许多常用的数学运算符号。
1 | num_list = [3.14, 1, 3, 92] |
1 | num_list = [[3.14, 1, 3, 92], [1, 2, 3, 4]] |
有时候我们需要对一些变量进行初始化, 我们就可以使用random模块来生成。random又分为多种函数: 1.random生成0~1之间的随机数、2.uniform生成均匀分布的随机数、3.randn生成标准正态的随机数、4.normal生成正态分布的、5.shuffle随机打乱顺序、6.seeb设置种子. 如下代码:
1 | # 你每次执行都是不一样的结果 |
我的打印结果:
1 | [[0.0818346 0.23860994 0.64879857] |
可以生成一些特殊矩阵, 直接上代码:
1 | # 3×3矩阵,矩阵元素均为0 |
将数据保存到磁盘然后读取
1 | nd1 = np.random.random([3, 3]) |
arange是numpy模块中的函数, 废话少说, 实践出真知:
1 | # 从0到10,每次加一生成的数组 |
可以看见, 该函数格式为: arange([start], stop, [step], dtype=None), start和stop指定范围, start默认为0, stop必须指定, step为步长。
1 | nd = np.diag([1, 2, 3, 4, 5, 6, 7, 8]) |
以上操作仅仅是操作矩阵的行, 如要操作列, 继续往下
1 | nd = np.arange(25).reshape([5, 5]) |
以上学会了吗?
另外, 还可以通过random.choice函数从指定的样本随机抽取数据, 此处略。
1 | nd = np.arange(9).reshape([3, 3]) |
我们在上面使用了 numpy.linalg的函数, 下面咱们整理了一份表( numpy.linalg常用的函数):
| 函数 | 说明 |
|---|---|
| diag | 一维数组的形式返回方阵的对角线元素 |
| dot | 矩阵乘法 |
| trace | 求迹, 对角线元素之和 |
| det | 计算矩阵列式 |
| eig | 计算方阵的特征值与特征向量 |
| inv | 计算方阵的逆 |
| qr | 计算qr分解 |
| svd | 计算奇异值分解svd |
| solve | 解线性方程组: Ax=b, 其中A为方阵 |
| lstsq | 计算Ax=b的最小二乘解 |
当初学习Java的时候并没有特别去学习和理解注解(Annotation),写了一段时间springboot项目之后,准备回来重修。
所谓注解(Annotation),其实就是代码里的特殊标记,能够在代码编译、类加载、运行的时候被读取并对它进行相应的处理。说白了其实可以理解为“贴在代码上的便签”,通过使用注解使得程序开发在不改变程序原有逻辑的基础上,在源文件里嵌入一些补充信息。
注解其实可以为程序元素(类、方法、成员变量等)设置元数据,但到底啥是设置元数据,往后面看就行了。
需要注意的一点是,注解实际上并不影响程序执行,但是你若想要它发挥一定的做用,你就得通过配套工具对注解中的信息进行处理,就相当于是你在代码上贴了“标签”,你得写一段程序来检查这个“标签”
这个注解我们太熟悉了!强制子类重写父类方法,它能帮助程序员放置一些低级错误:重写的方法名写错了等
只要重写的方法名不一致就会报错
1 | class father { |
用于标注某个类、方法已过时,当被使用的时候会报警告
这个注解有两个属性:
- since:该元素哪个版本会过时
- forRemoval:该元素在将来是否会被删除
1 | // 注意:这个注解时JDK9之后的增强版 |
感觉这俩注解没啥好说的,我们一般也不会用到
- @SuppressWarnings就是可以让程序元素不报警,包括这个程序元素的所有子元素
- @SafeVarargs防止堆污染
保证某个接口一定是函数式接口,即只含有抽象函数的接口,他只能修饰接口
1 |
|
所谓元注解,就是修饰注解的注解(禁止套娃!),我们先来康康几个常用的注解吧
@Retention指定被修饰的注解可以存活多长时间,他的value值为以下三个
RetentionPolicy.SOURCE–编译器把注解记录在文件中,当运行Java程序时,JVM不可获取注解信息
RetentionPolicy.CLASS–编译器把注解记录在文件中,当运行Java程序时,JVM可以通过反射获取注解信息
RetentionPolicy.RUNTIME–只保留在源码中,编译器直接丢弃,例如@data注解,他只是在编译时候让编译器给类加上getter setter之后就被丢弃了
1 | // @data注解 |
@Target指定被修饰的注解能修饰哪些程序单元,这里有很多,就不细讲了,咱们举一个栗子吧!
ElementType.TYPE–可以修饰类、接口(包括注解类型)、枚举定义
1 | // 这是ElementType枚举类内部 |
被@Documented修饰的注解可以被javaDoc工具提取成文档
@Inherited修饰的注解具有继承性,如@Inherited修饰了@a注解,而@a修饰了father这个基类,则father的子类son也相当于被@a修饰
可能有点绕哈,来人!上代码!
定义注解:
1 | // 这是被@Inherited修饰的接口 |
定义类:
1 | //@inheritedTest具有继承性 |
其实注解就是接口,所以定义注解和定义接口差不多,在关键字
interface前加一个@即可,如下定义@MyTag注解:
1 | public MyTag { |
成员变量在注解定义中以无参方法的形式来声明,方法名和返回值分别为变量的名字与类型,如下
1 | public MyTag { |
废话不多说,直接上代码!!!
1 | public class getInfoTest { |
之前写项目遇到过一个问题:如何比较自由的拦截token
以前是直接写一个拦截类然后再写一个配置类从而达到拦截部分请求的目的
使用注解解决方法如下:
定义了注解的目标以及存活时间
1 |
|
拦截器就是处理这个”标签”工具
1 | public class AuthenticationInterceptor implements HandlerInterceptor { |
关于Java注解可以学的东西还有很多,这篇文只讲了其中很小一部分,希望继续多多钻研。
本章我们学习了6种符号表的实现下面是其简单预览:
| 使用的数据结构 | 实现 | 优点 | 缺点 |
|---|---|---|---|
| 链表(顺序查找) | SequentialSearchST | 适用于小型问题 | 对于大型符号表很慢 |
| 有序数组(二分查找) | BinarySearchST | 最优的查找效率和空间需求,能够进行有序性的相关操作 | 插入操作很慢 |
| 二分查找树 | BST | 实现简单,能够进行有序性的相关操作 | 没有性能上界的保证 链接需要额外的空间 |
| 平衡二叉查找树 | RedBlackBST | 最优的查找和插入效率,能够进行有序性的相关操作 | 链接需要额外的空间 |
| 散列表 | SeparateChainHashST LinearProbingHashST |
能够快速的查找和插入常见类型的数据 | 需要计算每种类型的数据散列 无法进行有序性的相关操作 链接和空结点需要额外的空间 |
使用散列查找算法分为两步:1、使用散列函数将键转化为数组的一个索引;2、处理哈希碰撞冲突的过程
两种解决哈希碰撞的方法:拉链法和线性探测法
如果我们有一个能保存M个键值对的数组,那么我们就需要一个能将任意键转化为该数组范围内(0~M-1)索引的散列函数
下面我们来看看对不同键的散列函数
正整数
除留余数法
浮点数
乘上实数
字符串
散列函数的第二步是处理哈希碰撞,也就是处理两个或多个键相同的情况,一种直接的办法就是:将大小为M的数组中的每个元素指向一条链表,链表中的每个节点都存储了散列值为该元素的索引的键值对,此乃 拉链法。
实现散列表的另一种方式是用大小为M的数组保存N个键值对(M>N)。我们需要依靠数组中的空位解决冲突。基于这种策略的所有方法都被称为开放地址散列表。
开放地址散列法中最简单的就是线性探测法:当碰撞发生时,我们直接检查散列表的下一个位置(索引+1),这样线性探测就会发生下面三种情况:
计算机发展早期,符号表帮助程序员从使用机器语言的数字进化到汇编语言中使用符号名称
小小的总结:
renren-fast是一个轻量级的Spring Boot2.1快速开发平台,它能快速帮我们搭建好一个项目以及生成一些基本的增删改查代码,介样的话我们就能更好地专注于我们自己的一些业务,真香!!!
那么下面我们就开始吧!
我们要先自己创建好数据库,由于自己刚好要写项目,于是我自己就创建的下面这一个springboot项目:
人人开源官方gitee地址:人人开源
来到官方网址以后,咱找到仓库里的renren-generator(如下),将他的项目整个clone到我们自己的电脑上。可以看到他有好几个开源项目,之后我们都可以去试试他们
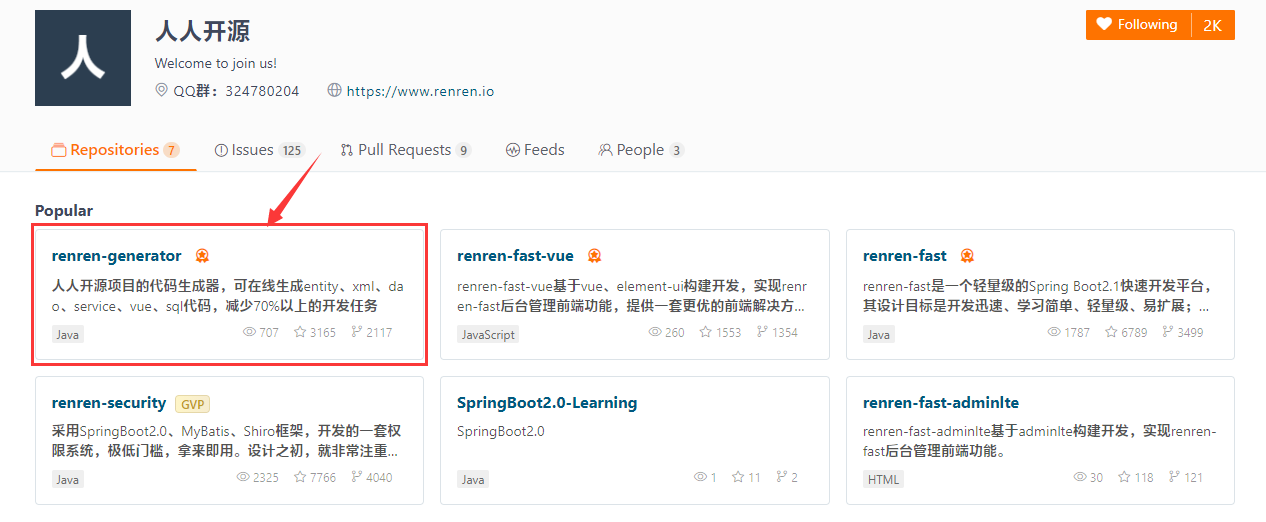
我们先用IDEA打开我们刚刚下载好的项目,打开我们的application.yml配置文件,修改url、username、password

我们再来到generator.properties中,跟据自己的项目来修改即可
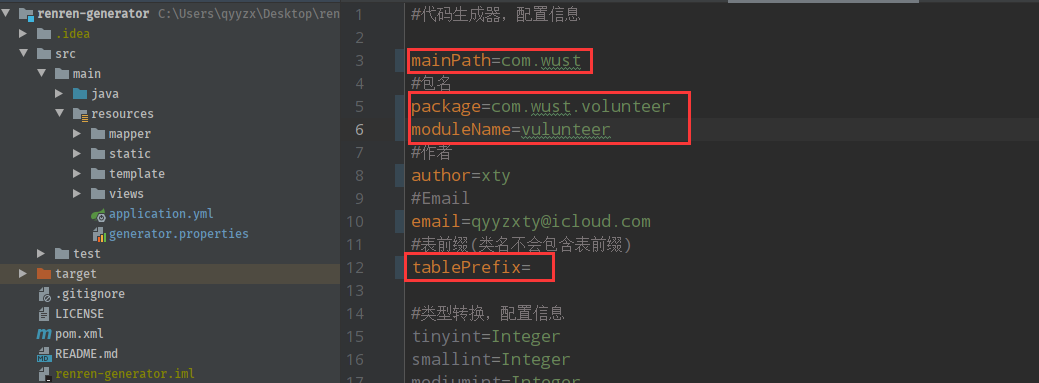
来到/resource/template下(如下图),其实模板里面就是对应着代码的生成规则(controller、dao、entity等),我们将Controller.java.vm里的这段代码@RequiresPermissions("${moduleName}:${pathName}:list")注释掉,记得有5个!然后删除import org.apache.shiro.authz.annotation.RequiresPermissions;就可以啦!
激动的心,颤抖的手终于可以生成代码了嘿嘿嘿,我们先来启动我们的项目,并在浏览器中访问localhost
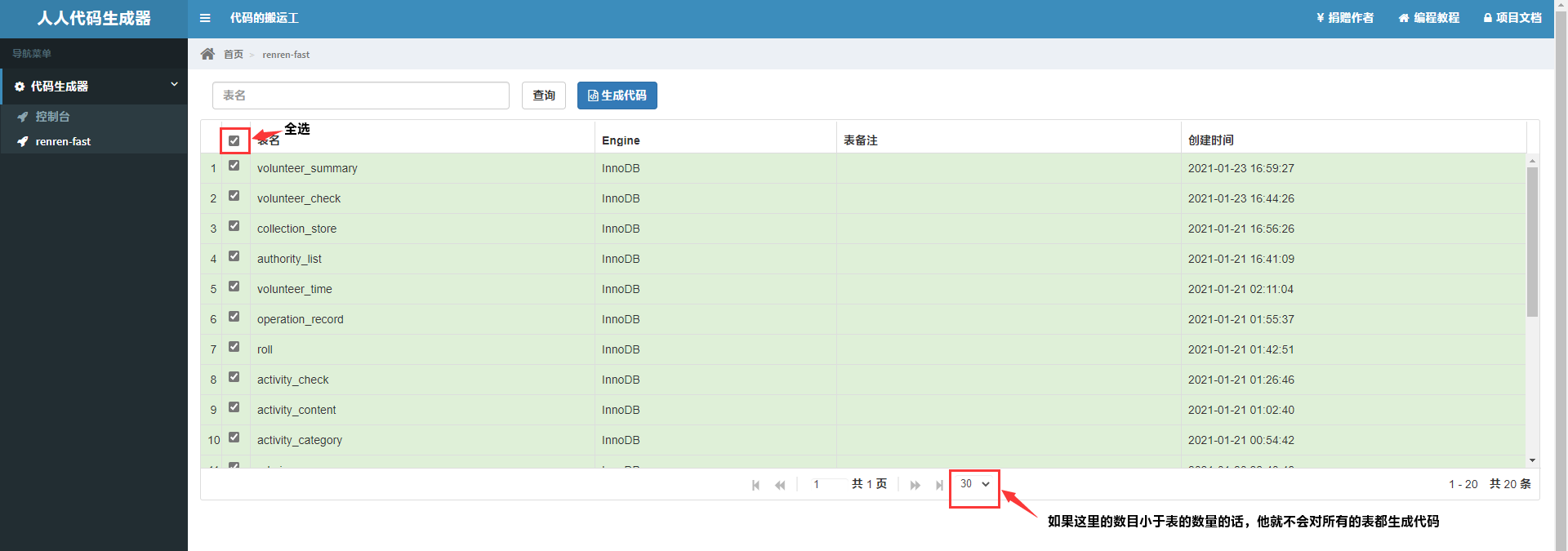
生成的压缩包,直接把main文件夹复制粘贴到自己的项目就好啦!
自动生成的代码我们还要进行亿点点修改
1 | <!-- spring-web框架 --> |
https://www.yuque.com/u21195183/jvm/ar6bqp#60990303
Java虚拟机栈(Java Virtual Machine Stack),早期也叫Java栈,其内部保存着一个一个栈帧(Stack Frame),对应着一次一次的Java方法调用,为线程私有
也称之为局部变量数组或本地变量表
定义为一个数字数组,主要用于存储方法参数和定义在方法体内部的局部变量,这些数据类型包括基本数据类型、对象引用、returnAdress类型
局部变量表建立在线程的栈上,线程的私有数据
所需要的容量大小在编译期间就确定了
关于Slot的理解
局部变量表中最基本的存储单元就是Slot
变量的分类:
按照数据类型分类:
1、基本数据类型
2、引用数据类型
按照在类中声明的位置分类:
1、成员变量(在使用前都经历过默认初始化赋值):类变量、实例变量
类变量:linking的prepare阶段给类变量默认赋值—>initial阶段给类变量显式赋值即静态代码块赋值
实例变量:随着对象的创建会在堆空间中分配实例变量空间,并进行默认赋值
2、局部变量
在使用前必须要进行显式赋值
补充说明:
在栈帧中,与性能调优关系最为密切的部分就是局部变量表,方法执行时虚拟机使用局部变量表完成方法的传递
局部变量表中的变量也是重要的垃圾回收根节点
主要用于保存计算过程的中间结果,同时作为计算过程中变量临时的存储空间
当一个方法执行的时候,一个新的栈帧也会随之创建出来,这个方法的操作数栈是空的
操作数栈虽然是数组,但是不能通过访问索引的方式来进行数据访问
如果被调用方法带有返回值的话,返回值也会压入当前栈帧的操作数栈中
常量池:Constant Pool
在Java源文件被编译到字节码文件中时,所有的变量和方法引用都作为符号引用(Symbolic Reference)保存在文件的常量池里
例如:描述一个方法引用另一个方法时就是通过常量池中指向的方法的符号引用来表示的
那么动态链接的作用就是为了将这些符号引用转换为调用方法的直接引用
方法的绑定机制:
虚方法和非虚方法
子类对的多态性的使用前提:类的继承关系、方法的重写
虚拟机提供了几条方法调用指令:
生命周期与线程一致
保存局部变量、部分结果,并参与方法的调用与返回
局部变量 VS 成员变量
基本数据变量 VS 引用类型变量(类、数组、接口)
(1)快速有效的分配存储方式
(2)JVM对Java栈的操作只有两个
每个方法执行,伴随着进栈(入栈、压栈)
执行结束后的出栈工作
(3)对于栈来说不存在垃圾回收的问题
GC、OOM
StackOverflowError、OutOfMemoryError
追踪的代码如下:
1 | public class OperandStackTest { |
之后进行编译,得到字节码文件:
然后对得到的字节码文件进行反解析:
1 | javap -verbose OperandStackTest.class |
也可以直接使用jclasslib插件直接解析:

该方法对应的字节码指令为:
1 | 0 bipush 15 |
执行引擎将字节码指令翻译成机器指令
我们再添加一些代码,重新编译:
1 | public int getSum() { |
看看testGetSum()方法反编译结果:
1 | 0 aload_0 |
aload_0中的0正是局部变量表里的Slot 0的含义,从局部变量表0的位置加载,也就是 this的位置
i++和++i的区别:
1 | public void add() { |
笔记来源:
对于Java的函数式编程,做一些摘抄以及总结,我是一个快乐的搬运工
~
Lambda表达式,也可称为闭包,它是推动 Java 8 发布的最重要新特性,它允许把函数作为一个方法的参数,使代码变的更加简洁紧凑,它允许使用更简洁的代码来创建一个只有一个抽象方法的接口(这种接口被称为函数式接口)的实例。
下面用一个小例子来简单说明
以Comparator为例,我们想要调用Arrays.sort()时,可以传入一个Comparator实例,以匿名类方式编写如下
1 | String[] strings = new String[] {"Apple", "Orange", "Banana", "Lemon"}; |
从Java 8开始,我们可以用Lambda表达式替换 单方法 接口(注意是单方法!!!)如下
1 | Arrays.sort(strings, (s1, s2) -> { |
其中,参数是(s1, s2),参数类型可以省略,因为编译器可以自动推断出String类型。-> { ... }表示方法体,所有代码写在内部即可,返回值的类型也是由编译器自动推断的,这里推断出的返回值是int,因此,只要返回int,编译器就不会报错。
从上面的例子可以看出:Lambda的代码块会代替实现抽象方法的方法体,Lambda就相当于一个匿名的方法。
Lambda表达式的类型,也被称为目标类型(target type),Lambda的目标类型必须是函数式接口(functional interface)。所谓函数式接口就是只包含一个抽象方法的接口(但是可以包含多个默认方法,类方法,但是只能声明一个抽象方法)。例如 Runnable、ActionListener都是函数式接口。
Java8专门为函数式接口提供了
@FunctionalInterface注解,它用于告诉编译器严格检查–检查该接口必须是函数式接口,否则编译器报错。
由于Lambda表达式的结果就是被当成对象,因此可以直接进行赋值如下
1 | Runnable runnable = () -> { |
Runnable接口只包含一个无参数的方法,Lambda实现了该接口中唯一的、无参数的方法,因此就实现了一个Runnable对象
Runnable是Java本身提供的一个函数式接口
从以上分析可知Lambda表达式实现的是匿名方法,它有以下两个限制:
如果Lambda代码块中只有一条代码,程序就可以省略Lambda中的花括号,甚至还能进行方法引用与构造器引用
先直接上代码:
1 | public class Lambda { |
函数式包含一个convert的抽象方法,将String转成Integer,由于表达式所实现的convert()需要返回值,所以Lambda把这条代码作为返回值。上面的代码块只有一行调用类方法的代码,因此可以使用如下方法进行替换:
1 | Convert convert = Integer::valueOf; |
调用Integer类方法中的valueOf()方法来实现Convert接口的唯一的抽象方法。
看看下面的示例:
1 | Convert convert = form -> "fkit.org".indexOf(form); |
convert()方法执行体就是Lambda表达式的代码块部分,下面请看方法引用代替Lambda,引用特定对象的实例方法:
1 | Convert convert = "fkit.org"::indexOf; |
下面直接先看看代码:
1 | public class Lambda { |
上面的Lambda的代码块只有a.substring(b, c),使用了a这个String对象的substring()方法,当然下面的代码也能实现:
1 | MyTest myTest = String::substring; |
对于上面这个实例的方法引用,方法引用代替Lambda表达式,引用某类的某类对象的实例方法,函数式接口中被实现方法的第一个参数作为调用者,后面的参数全部传给该方法作为参数。
下面看构造器引用:
1 | public class Lambda { |
上面代码调用myTest对象的win()方法时,myTest对象就是Lambda表达式创建的,因此代码块的执行体就是new JFrame(a)并将这条语句的返回值作为方法的返回值。同样的,我们也可以用下面的代码去替换:
1 | MyTest myTest = JFrame::new; |
上面这种构造器引用代替Lambda的做法,函数式接口中被实现方法的全部参数传给该构造器作为参数。
从上面的种种实例可以看出Lambda表达式是匿名内部类的一种简化。
effectively finally的局部变量,以及外部类的成员变量(包括实例变量与类变量)下面是喜闻乐见的演示环节:
1 | public class Lambda { |
Arrays类有些方法需要实现Comparator、XxxOperation、XxxFunction等接口的实例,这些都是函数式接口,下面演示一个:
1 | public static void main(String[] args) { |
至此,Lambda算是简单入了一个门啦!!!
Java 8 API添加了一个新的抽象称为流Stream,可以让你以一种声明的方式处理数据,英语较好的同学建议直接看官方文档。
那么Stream究竟是啥呢?
我们来康康英文单词stream,解释为 溪流 小溪 数据流,其实Java中的Stream也是类似于这个的东西。
官方文档的第一句话A sequence of elements supporting sequential and parallel aggregate operations.,一个支持顺序和并行聚合的序列,这样说起来这个Stream和List有有啥区别呢?
List存储的每个元素都是已经存储在内存中的某个Java对象,而Stream输出的元素可能并没有预先存储在内存中,而是实时计算出来的。也就是说,如果我没有用到Stream中的元素,它就不存在,相当于Stream只是一个声明的作用。
接下来看一个例子:
1 | int sum = widgets.stream() |
这也是官方文档上的一个例子,widgets是一个Widget对象的一个Collection,我们创建了一个包含Widget对象的Stream;filter就是一个过滤器,他只留下了 red widgets;然后mapToInt将这条Stream变成了一个int的Stream,最后求和。
怎么样?通过这个小例子是不是对Stream有了一点点感觉呢?接下来我们就开始学习使用它吧!
1 | Stream<String> stream1 = Stream.of("A","B","C","D"); |
上面的例子传入了可变参数即创建了一个能输出确定元素的Stream。
1 | Stream<String> stream2 = Arrays.stream(new String[]{"A", "B", "C"}); |
stream2使用Arrays.stream()方法把传入的固定数组变成了Stream;
stream3是使用List.of()生成一个不可变数组,然后通过这个数组创建的流,需要注意的是,List.of()是在jdk1.8以后才出现的,所以在jdk1.9版本及以后才能运行;
stream4是list直接调用stream()方法获得的,Stream对于Collection(List、Set、Queue等),直接调用stream()方法就可以获得Stream,这种创建Stream的方法都是把一个现有的序列变为Stream,它的元素是固定的。
1 | public class StreamTest { |
stream5通过Stream.generate()方法创建的Stream,它需要传入一个Supplier对象,基于Supplier创建的Stream会不断调用Supplier.get()方法来不断产生下一个元素,这种Stream保存的不是元素,而是算法,它可以用来表示无限序列。
上述代码我们用一个Supplier<Integer>模拟了一个无限序列(当然受int范围限制不是真的无限大)。如果用List表示,即便在int范围内,也会占用巨大的内存,而Stream几乎不占用空间,因为每个元素都是实时计算出来的,用的时候再算。
通过一些API提供的接口创建Stream
例如,Files类的lines()方法可以把一个文件变成一个Stream,每个元素代表文件的一行内容:
1 | try (Stream<String> lines = Files.lines(Paths.get("/path/to/file.txt"))) {} |
另外,正则表达式的Pattern对象有一个splitAsStream()方法,可以直接把一个长字符串分割成Stream序列而不是数组:
1 | Pattern p = Pattern.compile("\\s+"); |
Stream.map()是Stream最常用的一个转换方法,它把一个Stream转换为另一个Stream;所谓map操作,就是把一种操作运算,把一个序列映射到另外一个序列的每一个元素上。
例如下面的一个例子,对x计算它的平方,可以使用函数f(x) = x * x,我们把这个函数映射到一个序列1,2,3,4,5上,就得到了另一个序列1,4,9,16:
1 | Stream<Integer> s1 = Stream.of(1,2,3,4); |
如果我们点进去查看Stream的源码:<R> Stream<R> map(Function<? super T, ? extends R> mapper);发现map()方法接收的对象是Function接口对象,而Function接口对象呢,它定义了一个apply()方法,负责把一个T类型转换成R类型:R apply(T t);,由此可见Stream.map()的功能。
下面我们看看他的简单应用:
1 | public class Main { |
Stream.filter()从字面也能理解,即过滤器。filter()方法原码:Stream<T> filter(Predicate<? super T> predicate);它定义了一个test()方法,再深入:boolean test(T t);可以看到这个方法负责判断元素是否符合条件。
1 | public class mapTest { |
可以看到,filter()除了常用于数值外,也可应用于任何Java对象,上面的例子就是从一组给定的LocalDate中过滤掉工作日,以便得到休息日。
map()和filter()都是Stream的转换方法,而Stream.reduce()则是Stream的一个聚合方法,它可以把一个Stream的所有元素按照聚合函数聚合成一个结果,下面看一个例子:
1 | public class Main { |
咱们依然是来先看看reduce()的源码:T reduce(T identity, BinaryOperator<T> accumulator); 可以看到reduce()方法传入的一个对象是BinaryOperator接口,继续前进,发现BinaryOperator接口继承了BiFunction<T,T,T>:public interface BinaryOperator<T> extends BiFunction<T,T,T> 最后终于在BiFunction中找到了R apply(T t, U u);这么一个方法,apply()方负责把上次累加的结果和本次的元素 进行运算,并返回累加的结果。
聊了这么多,最终的结果就是我们在reduce()方法中传入的Lambda表达式(acc, n) -> acc + n实现了R apply(T t, U u);,并将聚合的结果给了acc返回,而传入的第一个参数0的作用是初始化结果为0。
除了求和,还有求积:
1 | public class Main { |
除了可以对数值进行累积计算外,灵活运用reduce()也可以对Java对象进行操作。下面的代码演示了如何将配置文件的每一行配置通过map()和reduce()操作聚合成一个Map<String, String>:
1 | public class Main { |
我们来看看上面的程序,理一下思路:
首先,我们先创建一个String类型的List即props,props.stream()将props变成一条Stream,然后在.map()中将Stream中的每一个String对象都进行了分割,两段字符串分别存在ss[0], ss[1]中,并调用 Map.of(ss[0], ss[1])将每一个对象都变成了一个Map对象,最后在.reduce()方法中,初始值为一个HashMap<String, String>()对象,将Stream中的每一个Map对象放到HashMap<String, String>()集合中并返回。
费了好一番口舌,还是感觉原理有一点难理解,建议多看看源码。
前面介绍了Stream的几个常见操作:map()、filter()、reduce()
这些操作对Stream来说可以分为两类,
map()和filter()reduce()我们要知道对于Stream来说,对其进行转换操作并不会触发任何计算!如下
1 | public class Main { |
而聚合操作则不一样,聚合操作会立刻促使Stream输出它的每一个元素,并依次纳入计算,以获得最终结果,如下
1 | Stream<Long> s1 = Stream.generate(new NatualSupplier()); |
如果我们将Stream<Long> s4 = s3.limit(10);注释掉,就会发生错误,其原因就是聚合操作会即时计算。
可见,聚合操作是真正需要从Stream请求数据的,对一个Stream做聚合计算后,结果就不是一个Stream,而是一个其他的Java对象。
因为List的元素是确定的Java对象,因此,把Stream变为List不是一个转换操作,而是一个聚合操作,它会强制Stream输出每个元素。
1 | Stream<String> stream = Stream.of("Apple", "", null, "Pear", " ", "Orange"); |
把Stream的每个元素收集到List的方法是调用collect()并传入Collectors.toList()对象,它实际上是一个Collector实例,通过类似reduce()的操作,把每个元素添加到一个收集器中(实际上是ArrayList),类似的,collect(Collectors.toSet())可以把Stream的每个元素收集到Set中。
把Stream的元素输出为数组和输出为List类似,我们只需要调用toArray()方法,并传入数组的“构造方法”:
1 | List<String> stringList = List.of("Apple", "Banana", "Orange"); |
如果我们要把Stream的元素收集到Map中,可以使用之前的先转换再聚合的方法
1 | Stream<String> streamm = Stream.of("APPL:apple", "MSFT:Microsoft"); |
当然我们还有其他方法,我们可以指定两个映射函数,分别把元素映射为key和value:
1 | streamm = Stream.of("APPL:apple", "MSFT:Microsoft"); |
Stream还有一个强大的分组功能,可以按组输出。我们看下面的例子:
1 | List<String> Fruit = List.of("Apple", "Banana", "Blackberry", "Coconut", "Avocado", "Cherry", "Apricots"); |
分组输出使用Collectors.groupingBy(),它需要提供两个函数:分组的key与分组的value
分组的key这里使用s -> s.substring(0, 1),表示只要首字母相同的String分到一组
分组的value这里直接使用Collectors.toList(),表示输出为List
假设有这样一个Student类,包含学生姓名、班级和成绩:
1 | class Student { |
如果我们有一个Stream
如下面的例子:
1 | public class test { |
Stream提供的操作分为两类:转换操作和聚合操作。除了前面介绍的常用操作外,Stream还提供了一系列非常有用的方法。
对Stream的元素进行排序十分简单,只需调用sorted()方法,此方法要求Stream的每个元素必须实现Comparable接口。如果要自定义排序,传入指定的Comparator即可:
1 | List<String> list = List.of("hello", "xty", "xwy", "jhl", "aaa") |
注意sorted()只是一个转换操作,它会返回一个新的Stream,所以我们后来要.collect(Collectors.toList());把它变成一个List
对一个Stream的元素进行去重,没必要先转换为Set,可以直接用distinct():
1 | List<String> liss = List.of("A", "B", "A", "C", "B", "D").stream().distinct().collect(Collectors.toList()); |
截取操作也是一个转换操作,将返回新的Stream:
1 | liss = List.of("A", "B", "C", "D", "E", "F") |
将两个Stream合并为一个Stream可以使用Stream的静态方法concat():
1 | Stream<String> s1 = List.of("A", "B", "C").stream(); |
如果Stream的元素是集合:
1 | Stream<List<Integer>> s = Stream.of( |
而我们希望把上述Stream转换为Stream<Integer>,就可以使用flatMap():
1 | Stream<Integer> i = s.flatMap(list -> list.stream()); |
通常情况下,对Stream的元素进行处理是单线程的,即一个一个元素进行处理。但是很多时候,我们希望可以并行处理Stream的元素,因为在元素数量非常大的情况,并行处理可以大大加快处理速度。
把一个普通Stream转换为可以并行处理的Stream非常简单,只需要用parallel()进行转换:
1 | Stream<String> s = ... |
经过parallel()转换后的Stream只要可能,就会对后续操作进行并行处理。我们不需要编写任何多线程代码就可以享受到并行处理带来的执行效率的提升。
除了reduce()和collect()外,Stream还有一些常用的聚合方法:
count():用于返回元素个数;max(Comparator<? super T> cp):找出最大元素;min(Comparator<? super T> cp):找出最小元素。针对IntStream、LongStream和DoubleStream,还额外提供了以下聚合方法:
sum():对所有元素求和;average():对所有元素求平均数。还有一些方法,用来测试Stream的元素是否满足以下条件:
boolean allMatch(Predicate<? super T>):测试是否所有元素均满足测试条件;boolean anyMatch(Predicate<? super T>):测试是否至少有一个元素满足测试条件。Stream提供的常用操作有:
转换操作:map(),filter(),sorted(),distinct();
合并操作:concat(),flatMap();
并行处理:parallel();
聚合操作:reduce(),collect(),count(),max(),min(),sum(),average();
其他操作:allMatch(), anyMatch(), forEach()
1 | docker search nginx |
1 | docker pull nginx |
1 | docker images |
显示有以下这一行则表示拉取成功: nginx latest ae2feff98a0c 3 weeks ago 133MB
1 | docker run -d --name nginx01 -p 3344:80 nginx |
里面的 “-p 3344:80” 的意思是将 外部的 3344 端口映射到 容器内的 80 端口
1 | docker ps |
会显示以下提示信息:
1 | CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES |
测一测本机的 3344 端口,可以看到能访问到 nginx
1 | [root@iz2ze42tl10pjoj8i0za7hz ~]# curl localhost:3344 |
1 | docker exec -it nginx01 /bin/bash |
进来容器之后我们找一找配置文件,可以进行修改
1 | root@985e1a5fe8c2:/# whereis nginx |
修改 /opt/docker_redis/docker-compose.yml 文件,以方便后期修改 Redis 配置信息
1 | version: '3.1' |
redis的配置
1 | #redis的AUTH密码 |
介绍
MybatisPlus注解包相关类详解(更多详细描述可点击查看源码注释)
注解类包:
👉 mybatis-plus-annotation(opens new window)
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
|---|---|---|---|---|
| value | String | 否 | “” | 表名 |
| schema | String | 否 | “” | schema |
| keepGlobalPrefix | boolean | 否 | false | 是否保持使用全局的 tablePrefix 的值(如果设置了全局 tablePrefix 且自行设置了 value 的值) |
| resultMap | String | 否 | “” | xml 中 resultMap 的 id |
| autoResultMap | boolean | 否 | false | 是否自动构建 resultMap 并使用(如果设置 resultMap 则不会进行 resultMap 的自动构建并注入) |
| excludeProperty | String[] | 否 | {} | 需要排除的属性名(@since 3.3.1) |
关于autoResultMap的说明:
mp会自动构建一个ResultMap并注入到mybatis里(一般用不上).下面讲两句: 因为mp底层是mybatis,所以一些mybatis的常识你要知道,mp只是帮你注入了常用crud到mybatis里 注入之前可以说是动态的(根据你entity的字段以及注解变化而变化),但是注入之后是静态的(等于你写在xml的东西) 而对于直接指定typeHandler,mybatis只支持你写在2个地方:
insert和updatesql的#{property}里的property后面(例:#{property,typehandler=xxx.xxx.xxx}),只作用于设置值 而除了这两种直接指定typeHandler,mybatis有一个全局的扫描你自己的typeHandler包的配置,这是根据你的property的类型去找typeHandler并使用.| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
|---|---|---|---|---|
| value | String | 否 | “” | 主键字段名 |
| type | Enum | 否 | IdType.NONE | 主键类型 |
| 值 | 描述 |
|---|---|
| AUTO | 数据库ID自增 |
| NONE | 无状态,该类型为未设置主键类型(注解里等于跟随全局,全局里约等于 INPUT) |
| INPUT | insert前自行set主键值 |
| ASSIGN_ID | 分配ID(主键类型为Number(Long和Integer)或String)(since 3.3.0),使用接口IdentifierGenerator的方法nextId(默认实现类为DefaultIdentifierGenerator雪花算法) |
| ASSIGN_UUID | 分配UUID,主键类型为String(since 3.3.0),使用接口IdentifierGenerator的方法nextUUID(默认default方法) |
| ID_WORKER | 分布式全局唯一ID 长整型类型(please use ASSIGN_ID) |
| UUID | 32位UUID字符串(please use ASSIGN_UUID) |
| ID_WORKER_STR | 分布式全局唯一ID 字符串类型(please use ASSIGN_ID) |
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
|---|---|---|---|---|
| value | String | 否 | “” | 数据库字段名 |
| el | String | 否 | “” | 映射为原生 #{ ... } 逻辑,相当于写在 xml 里的 #{ ... } 部分 |
| exist | boolean | 否 | true | 是否为数据库表字段 |
| condition | String | 否 | “” | 字段 where 实体查询比较条件,有值设置则按设置的值为准,没有则为默认全局的 %s=#{%s},参考(opens new window) |
| update | String | 否 | “” | 字段 update set 部分注入, 例如:update=”%s+1”:表示更新时会set version=version+1(该属性优先级高于 el 属性) |
| insertStrategy | Enum | N | DEFAULT | 举例:NOT_NULL: insert into table_a(<if test="columnProperty != null">column</if>) values (<if test="columnProperty != null">#{columnProperty}</if>) |
| updateStrategy | Enum | N | DEFAULT | 举例:IGNORED: update table_a set column=#{columnProperty} |
| whereStrategy | Enum | N | DEFAULT | 举例:NOT_EMPTY: where <if test="columnProperty != null and columnProperty!=''">column=#{columnProperty}</if> |
| fill | Enum | 否 | FieldFill.DEFAULT | 字段自动填充策略 |
| select | boolean | 否 | true | 是否进行 select 查询 |
| keepGlobalFormat | boolean | 否 | false | 是否保持使用全局的 format 进行处理 |
| jdbcType | JdbcType | 否 | JdbcType.UNDEFINED | JDBC类型 (该默认值不代表会按照该值生效) |
| typeHandler | Class<? extends TypeHandler> | 否 | UnknownTypeHandler.class | 类型处理器 (该默认值不代表会按照该值生效) |
| numericScale | String | 否 | “” | 指定小数点后保留的位数 |