题目链接:https://leetcode-cn.com/problems/two-sum/
题目描述
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。你可以按任意顺序返回答案。
题目分析
使用哈希表解题,贼舒服。
Java题解
1 | public class Solution { |
题目链接:https://leetcode-cn.com/problems/two-sum/
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。你可以按任意顺序返回答案。
使用哈希表解题,贼舒服。
1 | public class Solution { |


$1、$2、$3......$n function_name $1 $21 | Test() |
1 | Test |
写一个nginx脚本,如果nginx服务宕掉,则该服务可以检测并且将进程重新启动;如果正常运行,则不作任何处理
1 | !/bin/bash |


写一个脚本,该脚本可以实现计算器的功能,可以进行 +、-、*、/四种运算
1 | !/bin/bash |
获取系统中所有的用户
1 | !/bin/bash |
定义变量时,使用 local关键字
函数内和外若存在同名变量,则函数内部变量会覆盖外部变量
1 | !/bin/bash |
1 | function add |
1 | !/bin/bash |
控制平面作为一种网络范围

示例:
1、定义变量
1 | va_1="i love you, do you love me?" |
2、打印看看
1 | echo $va_1 |
显示如下字符串: i love you, do you love me?
3、进行字符替换
1 | var1=${va_1#*ov} |
var1如下所示: e you, do you love me?

语法: expr index $string $substring
语法: expr match $string substr
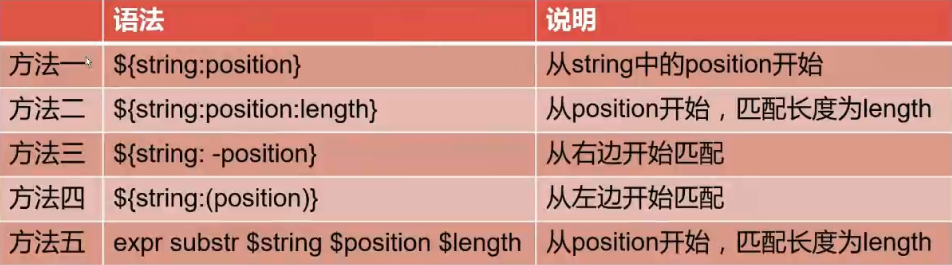
问题如下:

Shell脚本如下:
1 | !/usr/bin/env bash |
一段命令的执行结果是另一个命令的一部分,类似于函数引用

例子1
获取系统所有用户并输出
1 | !/bin/bash |
例子2
查看系统nginx进程是否存在,若不存在就启动它
1 | !/bin/bash |



注意!当使用两变量做比较使用 |、&、<、>、<=、>=符号的时候,需要进行转义,如下:
1 | expr $num1 \>= $num2 |

1 | num3=`expr $num1 + $num2` |
提示用户输入一个正整数num,然后计算1+2+3+4+···+num的值,必须对num是否为正整数做判断,不符合的话应当进行再输入
1 | !/bin/bash |
Shell脚本中 $0、$?、$!、$$、$*、$#、$@等的意义说明:
$$
Shell本身的PID(ProcessID,即脚本运行的当前 进程ID号)
$!
Shell最后运行的后台Process的PID(后台运行的最后一个进程的 进程ID号)
$?
最后运行的命令的结束代码(返回值)即执行上一个指令的返回值 (显示最后命令的退出状态。0表示没有错误,其他任何值表明有错误)
$-
显示shell使用的当前选项,与set命令功能相同
$*
所有参数列表。如”$*”用「”」括起来的情况、以”$1 $2 … $n”的形式输出所有参数,此选项参数可超过9个
$@
所有参数列表。如”$@”用「”」括起来的情况、以”$1” “$2” … “$n” 的形式输出所有参数
$@
跟$*类似,但是可以当作数组用
$#
添加到Shell的参数个数
$0
Shell本身的文件名
$1~$n
添加到Shell的各参数值。$1是第1参数、$2是第2参数…、
简单介绍:


1 | echo "scale=4;23.33+24" | bc |
|表示将前一条命令的输出,用作后一条命令的输入
排队的分组如何经输出链路传输的问题
如今有两个版本的IP正在使用:IPv6和IPv4
一个链路层帧能承载的最大数据量叫做最大传送单元(Maximum Transmission Unit,MTU)
IPv4的设计者决定将数据报的重新组装工作放到端系统中
主机与物理链路之间的边界叫做接口(interface),从技术上讲,一个IP地址与一个接口相关联,而不是与包括该接口的主机或者路由器相关联。
NAT路由器
32比特的IP地址即将分配完,所以开发了新的IP协议:IPv6
我们讨论了网络层的数据平面(data plane)功能,即每台路由器的如下功能:决定到达输入链路之一的分组如何转发到该路由器的输出链路之一
运输层位于应用层与网络层中间,为不同主机上的应用进程之间的通信起着至关重要的作用。还有两个非常重要的协议:TCP和UDP运输层协议。
总结一下UDP和TCP最基本的责任:将两个端系统间IP的交付服务拓展为运行在端系统上的两个进程之间的交付服务。
将主机间交付拓展到进程间交付被称为运输层的多路复用(transport-layer multiplexing)与多路分解(demultiplexing)。
进程到进程之间的数据交付和差错检测是两种最低限度的运输层服务
网络层提供的主机到主机之间的服务 - 变成 - 运行在主机上的应用程序进程到进程之间的服务
将运输层报文段中的数据交付到正确的套接字(socket)
在源主机从不同套接字中收集数据块,并为每个数据块封装上首部信息(用于以后的多路分解)
无连接的,运输层之间没有握手
选择UDP的原因:
关于发送什么数据以及何时发送的应用层控制更为精细
无需连接建立
无连接状态
分组首部开销小
TCP报文段有20字节的首部开销,UDP仅有8字节的开销
只有四个字段:源端口号、目的端口号、长度、检验和
每个字段两个字节(16bit)
长度字段指示了UDP报文段中的字节数(首部+运送的数据)
检验和用来检查报文段中是否出现了错误,实际上,计算校验和时,还包括了IP首部的一些字段
为什么UDP也要提供校验和?
因为不能保证源和目的之间所有的链路都提供差错检测
停止等待协议==》滑动窗口协议==》选择重传协议
| 机制 | 用途和说明 |
|---|---|
| 检验和 | |
| 定时器 | |
| 序号 | |
| 确认 | |
| 否定确认 | |
| 窗口、流水线 |
TCP连接提供的是双全工服务
TCP将数据看成一个无结构的、有序的字节流,所以序号是建立在传送的字节流之上的
一个报文段的序号(sequence number for a segment)应该是该报文段首字节的字节流编号
主机A填充进报文段的确认号是希望从主机B收到的下一个字节的序号
TCP只确认该流中至第一个丢失字节为止的字节,所以TCP被称为累计确认(cumulative acknowledge)
三次握手的详细过程
为什么需要初始序号?为什么需要三次握手而不是两次握手?
四次挥手的详细过程
在CPU中:
不同的CPU有不同的寄存器,如8086CPU中就有: AX、BX、CX、DX、SI、DI、SP、BP、IP、CS、SS、DS、ES、PSW
接下来我们先来认识一部分寄存器
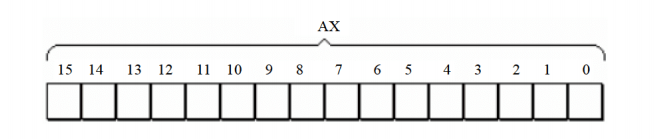
8086CPU的所有寄存器都是16位的,可以存放两个字节。AX、BX、CX、DX这个四个寄存器通常用来存放一般性的数据,被称为通用寄存器。
如AX的逻辑结构图如下所示:
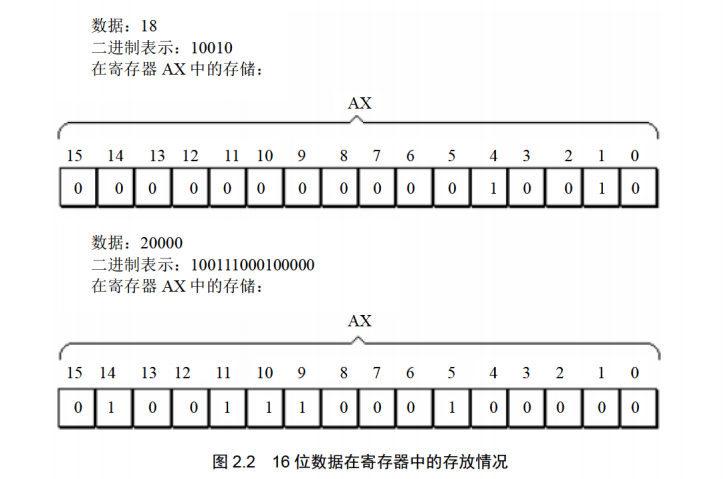
8086CPU上一代是8位的,为了保证兼容性,可以将AX、BX、CX、DX分为8个独立的寄存器来使用:
8086CPU的16位寄存器分为两个8位寄存器的情况如下所示:
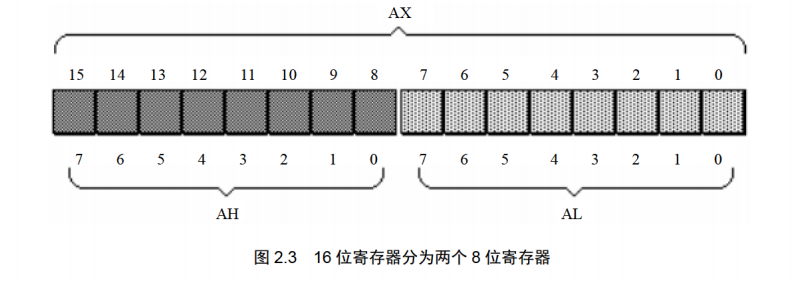
AX的低8位(o位7位)构成了AL寄存器,高8位(8位15位)构成了AH寄存器。AH和AL寄存器是可以独立使用的8位寄存器。图2.4展示了l6位寄存器及它所分成的两个8位寄存器的数据存储的情况。
出于兼容性的考虑,8086CPU可以一次性处理以下两种尺寸的数据:
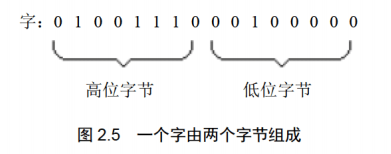
通过汇编指令控制CPU工作:

maven的生命周期:项目构建的各个阶段,包括 清理、编译、测试、报告、打包、安装、部署
插件:要完成项目的各个阶段,要使用maven命令,执行命令的功能是通过插件完成的。插件就是 jar,代表一些类。
命令:执行maven功能是由命令发出的,比如 mvn compile
单元测试(Junit):
Junit是一个单元测试的工具在Java中经常使用
单元:在Java中指方法,一个方法就是一个单元
作用:使用Junit来测试方法是否达标了
maven相关命令:
(1)mvn clean
(2)mvn compile:编译代码与拷贝文件
(3)