一、SpringWebFlux介绍
可以直接去官网看看:https://docs.spring.io/spring-framework/docs/current/reference/html/web-reactive.html
(1)是Spring5添加的新的模块,用于web开发的,功能与SpringMVC类似的,WebFlux使用的当前一种比较流行的响应式编程框架
(2)使用传统的web框架,比如SpringMVC,这些基于Servlet容器,WebFlux是一种异步非阻塞的框架,异步非阻塞框架在Servlet3.1以后才支持,核心是基于Reactor相关API实现的
(3)异步非阻塞:
异步与同步
针对调用者来说,调用者发送请求,如果等着对方回应之后才去做其他事情就是
同步;如果发送请求之后,不等对方回应就去做其他事情就是异步非阻塞与阻塞
针对被调用者而言,被调用者在收到请求之后,做完任务之后才给出反馈就是
阻塞;收到请求之后马上给出反馈然后再去做事情就是就是非阻塞
(4)WebFlux的特点:
- 1、非阻塞式:可以在有限的资源下,提高系统的吞吐量和伸缩性,以Reactor为基础实现函数式编程
- 2、Spring5基于Java8,WebFlux使用Java8函数式编程的方式实现路由请求
(5)与SpringMVC比较

- 1、上述两个框架都可以使用注解方式,都运行在Tomcat等容器中
- 2、SpringMVC采用命令式编程,WebFlux采用异步式响应编程
网关使用异步式响应编程更好,因为网关需要处理更多的请求
二、响应式编程(Java实现)
(1)什么是响应式编程
简称RP(Reactive Programming)
响应式编程是一种
面向数据流和变化传播的编程范式。这意味着可以在编程语言中很方便地表达静态或动态的数据流,而相关的计算模型会自动将变化的值通过数据流进行传播。
根据数据或者数据流发生变化,相应的计算模型就会根据值的变化而变化,例如:电子表格程序就是响应式编程的一个例子。单元格可以包含字面值或类似”=B1+C1”的公式,而包含公式的单元格的值会依据其他单元格的值的变化而变化。
(2)Java8及其之前的版本
提供了 观察者模式的两个类: Observer和 Observable。即观察你关心的数据的变化,一旦出现变化,就发出通知。
直接上代码,代码中我们设置了改变并进行了通知:
1 | public class ObserverDemo extends Observable { |
(3)Java9及其之后的版本
使用 Flow实现,这里直接看下面代码:
1 | //创建我自己的订阅者 |
三、响应式编程(Reactor实现)
(1)规范框架
响应式编程操作中, Reactor是满足 Reactive规范框架
(2)核心类
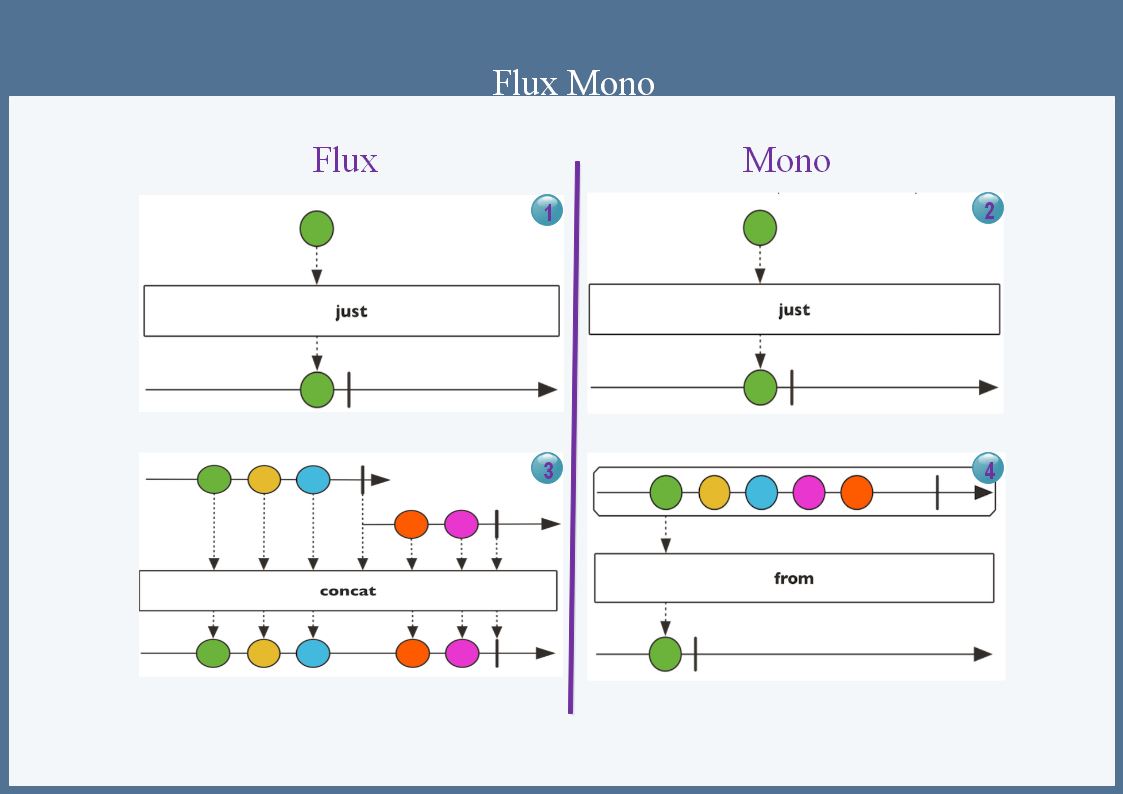
Reactor有两个核心类,Mono和 Flux,这两个类实现接口 Publisher,提供丰富操作符。 Flux对象实现发布者,返回N个元素; Mono实现发布者,返回0或者一个元素
(3)三种信号
Flux和 Mono都是数据流的发布者,使用 Flux和 Mono都可以发出三中信号:元素值、 错误信号、 完成信号(错误信号与完成信号用于告诉订阅者数据流结束了,他俩都是终止信号,错误信号在终止数据流时会同时将错误信息传递给订阅者)
以下图片说明了两者的区别(Flux返回0个或者多个元素,Mono返回一个元素):
(4)代码演示
接下来咱们直接在代码上来实现:
- 引入依赖
1 | <dependency> |
- 代码编写
1 | public class TestReactor { |
(5)三种信号的特点
- 错误信号和完成信号都是终止信号,是不能共存的
- 如果没有发送任何元素值,而是直接发送错误信号或者完成信号,表示的是空数据流
- 如果没有错误信号,没有完成信号,表示的是无线信号流
(6)订阅
调用 just或者其他方法只是声明数据流,数据流并没有发出,只有进行订阅之后才会触发数据流,不订阅啥都不会发生
1 | Flux.just(1,2,3,4).subscribe(System.out::println); |
(7)操作符
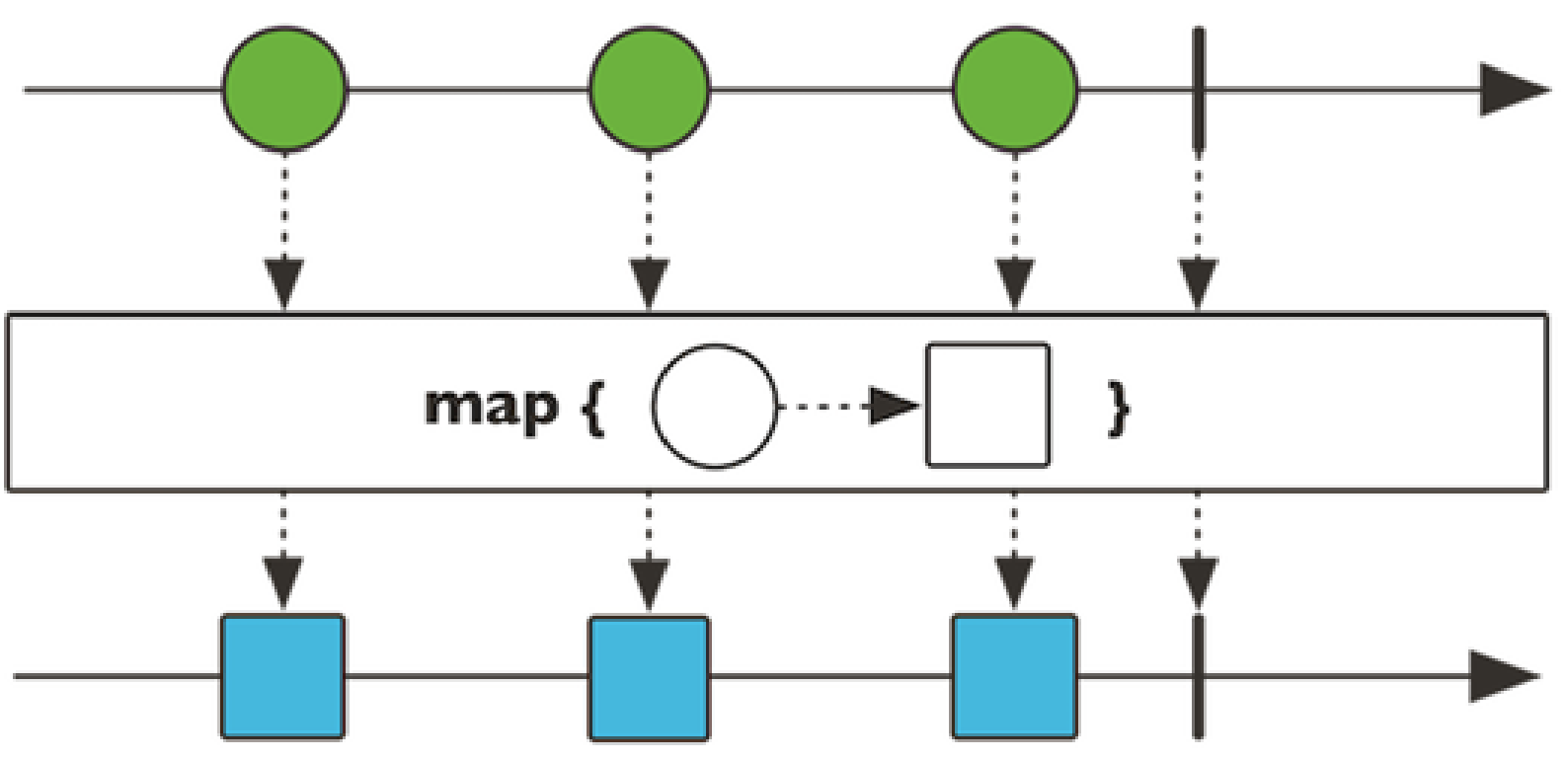
对数据流进行一道道操作,成为操作符,比如工厂流水线
map
将元素映射为新元素
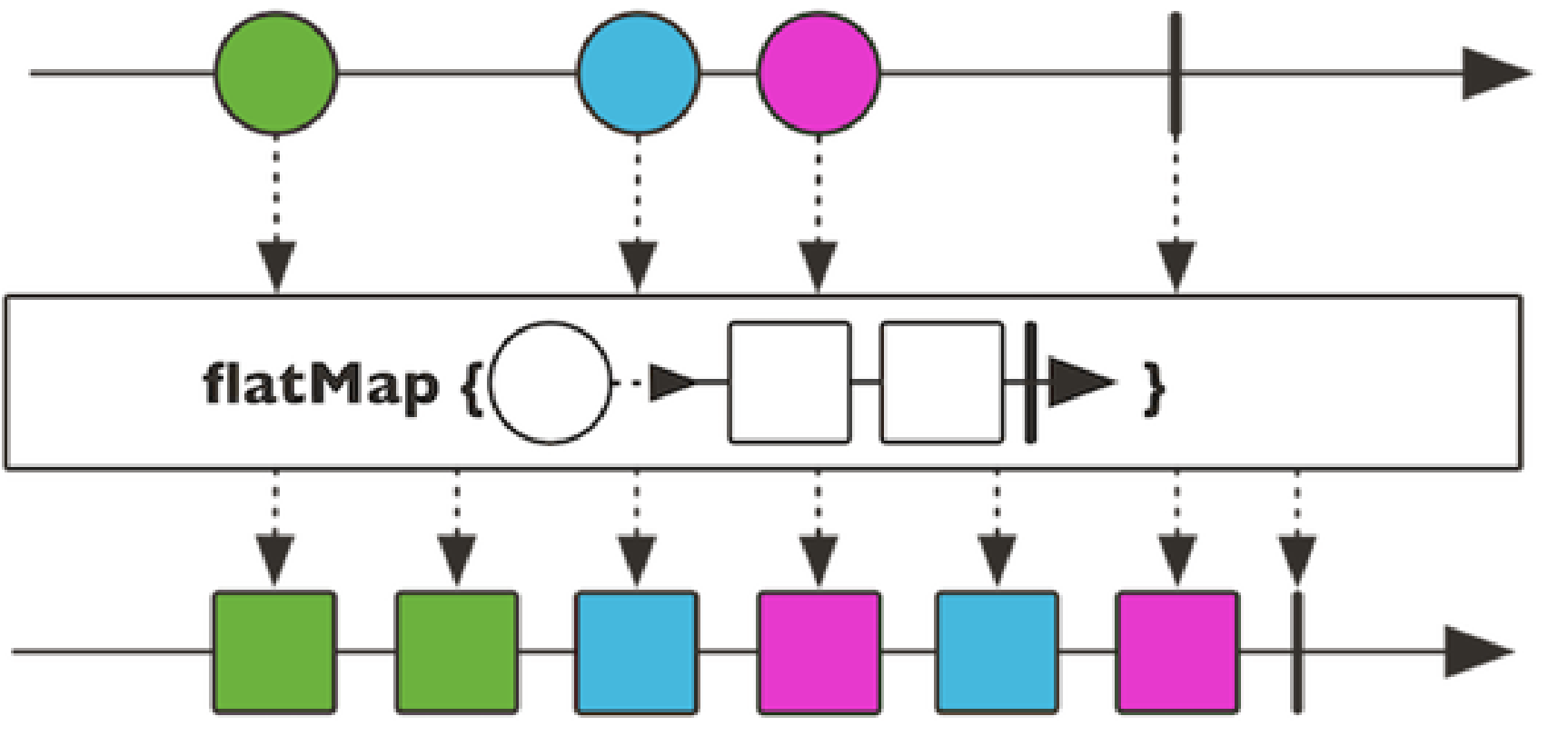
flatMap
将元素映射为流(将多个元素转成流,然后将多个流转成一个大流)
四、WebFlux执行流程和核心API
SpringWebFlux基于Reactor,默认使用的容器是Netty,Netty是高性能的NIO框架,异步非阻塞的框架
(1)Netty
- NIO(非阻塞)
- BIO(阻塞)
(2) SpringWebFlux执行过程和SpringMVC相似的
SpringWebFlux核心控制器DispatchHandler,实现接口WebHandler接口
WebHandler有一个方法:1
2
3public interface WebHandler {
Mono<Void> handle(ServerWebExchange var1);
}
(3)SpringWebFlux里面的DispatcherHandler,负责请求的处理
- HandlerMapping:请求查询到处理的方法
- HandlerAdapter:真正负责请求处理
- HandlerResultHandler:响应结果处理
(4)SpringWebFlux函数式编程
SpringWebFlux实现函数式编程,有两个接口: RouterFunction(路由处理)和 HandlerFunction(处理函数)
五、SpringWebFLux(基于注解编程模型)
SpringWebFlux实现方式有两种: 注解编程模型和 函数式编程模型
使用注解编程模型方式,和之前的 SpringMVC使用相似,只需要将相关依赖配置到项目中, SpringBoot自动配置相关运行容器,默认情况下使用Netty服务器
(1)创建SpringBoot工程,引入 WebFlux依赖
依赖如下:
1 | <dependency> |
(2)配置启动端口号
1 | =8081 |
(3)创建包和相关类
实体类
1
2
3
4
5public class User {
private String name;
private String gender;
private Integer age;
}接口定义操作
1
2
3
4
5
6
7
8public interface UserService {
//根据ID查询用户
Mono<User> getUserById(int id);
//查询所有用户
Flux<User> getAllUser();
//添加用户
Mono<Void> saveUserInfo(Mono<User> user);
}接口的实现类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
public class UserServiceImpl implements UserService {
//创建map集合存储数据
private final Map<Integer,User> users = new HashMap<>();
//无参构造
public UserServiceImpl() {
this.users.put(1,new User("lucy","nan",20));
this.users.put(2,new User("mary","nv",30));
this.users.put(3,new User("jack","nv",50));
}
//根据id查询
public Mono<User> getUserById(int id) {
return Mono.justOrEmpty(this.users.get(id));
}
//查询多个用户
public Flux<User> getAllUser() {
return Flux.fromIterable(this.users.values());
}
//添加用户
public Mono<Void> saveUserInfo(Mono<User> userMono) {
return userMono.doOnNext(person -> {
//向map集合里面放值
int id = users.size()+1;
users.put(id,person);
}).thenEmpty(Mono.empty());
}
}编写Controller层
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
public class UserController {
//注入service
private UserService userService;
//id查询
public Mono<User> geetUserId( int id) {
return userService.getUserById(id);
}
//查询所有
public Flux<User> getUsers() {
return userService.getAllUser();
}
//添加
public Mono<Void> saveUser( User user) {
Mono<User> userMono = Mono.just(user);
return userService.saveUserInfo(userMono);
}
}说明:
SpringMVC方式,同步阻塞的方式,基于SpringMVC + Servlet + TomcatSpringWebFlux方式,异步非阻塞的方式,基于SpringWebFlux + Reactor + Netty
六、SpringWebFLux(基于函数式编程模型)
在使用函数式编程模型操作的时候,需要自己初始化服务器
基于函数式编程模型的时候,有两个核心接口:
RouterFunction(实现路由的功能)和HandlerFunction(处理请求生成响应的函数)核心任务:定义两个函数式接口的实现并且启动需要的服务器
SpringWebFlux请求和响应不再是ServletRequest和ServletResponse
(1)创建Handler(具体实现方法)
1 | public class UserHandler { |
(2)初始化服务器,编写Router
1 | public class Server { |
(3)创建服务器完成适配
1 | public class Server { |
(4)最终调用
1 | public static void main(String[] args) throws IOException { |
(5)使用WebClient调用
1 | public class Client { |